Part 4
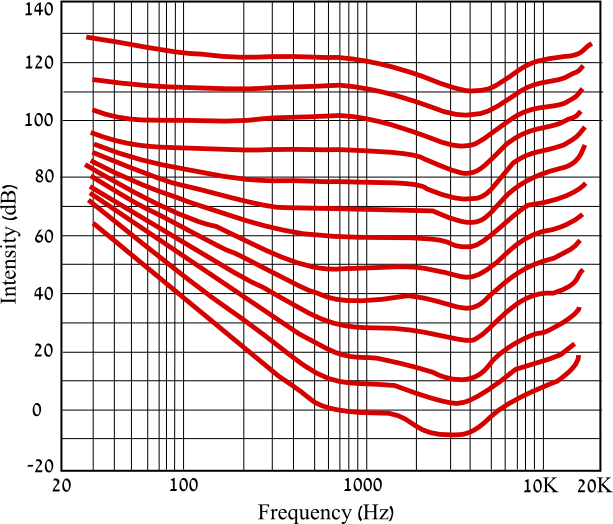
OK, so point two of what the ITU-R BS.1770 specification is attempting to define and standardise. For this we need to go back to Part 1 and the Fletcher/Munson Contours or rather we don't! Fletcher and Munson's experiments and studies have been repeated many times in the intervening years and indeed the ITU did hundreds themselves, over the course of several years. The end result was a single new contour, similar to Fletcher/Munson's but aligned with average TV listening volumes. This single contour can now be applied as a filter, to "weight" the output of each audio channel (the 5 main channels in 5.1 or the 2 channels in stereo), then the output from these weighted channels is summed together and averaged over time. The result is expressed in a new "loudness" scale. And to a large extent, this time it truly is a loudness scale (as we perceive loudness) because it accounts for our frequency dependent perception with the weighting. Although, we need to be aware that this weighting is not based on a scientific measurement, it is still impossible to measure a perception, it is the average of many hundreds of people's judgement of what sounds the same volume. Just wanted to be clear! BTW, the filter is officially called k-weighting and here is a plot of it:
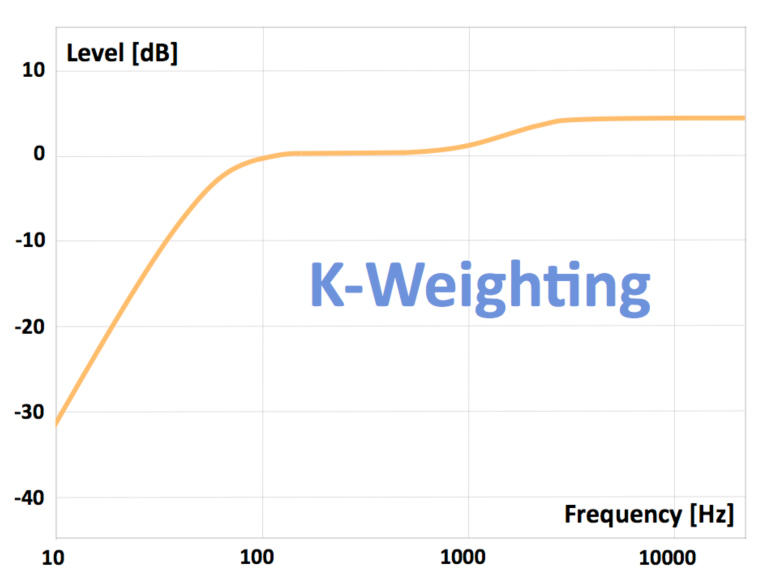
Notice for example the high shelf which starts at about 1kHz and reaches it's maximum at about 3kHz. What this means is that any 3kHz content in our mix is going to register on our loudness meter as 5dB higher than it actually is. Bang goes our trick of making our mix sound louder by concentrating energy in the most sensitive area of hearing. In fact, this k-weighting puts paid to ALL the frequency perception loopholes we used to exploit! And, summing and averaging (RMS) the k-weighted output also put's paid to all the compression, multi-band compression and limiting loopholes. The averaging is potentially a problem though, over what period of time do we average the signal? This new loudness normalisation paradigm includes 3 averages:
1. Momentary Loudness - averaged over 400ms (0.4secs).
2. Short-Term Loudness - averaged over 3 seconds and
3. Long-Term Integrated Loudness - averaged over the entire duration of the film/program.
For film/content makers it's really only the Integrated Loudness which is specified, Short-Term is usually only part of the specs for short duration content, roughly 30 secs or less; commercials, idents, etc.
So, now we've discussed all the main elements, we're just left with how they are applied in the ATSC A85 and EBU R128 specs. Well, just to confuse everyone, the loudness scale used by the ATSC and EBU have different names but both are based on exactly the same ITU standard and so for all intents and purposes are completely identical! The ATSC scale is called LKFS (Loudness K-weighted relative to Full Scale) and the EBU one is called LUFS (Loudness Units relative to Full Scale) but remember, they are equal, so for example; -18LUFS = -18LKFS.
For general programs the
ATSC specs are: -24LKFS ± 2LKFS (Integrated Loudness), peak limit -2dBTP.
For general programs the
EBU R128 specs are: -23LUFS ± 1LUFS (Integrated Loudness), peak limit -1dBTP.
Finally, we've got there! The keen eyed amongst you will have noticed that an EBU R128 compliant mix limited to -2dBTP would in fact also be an ATSC A85 compliant mix. In theory this is true but in practise some broadcasters are tending towards strict adherence and only accept an LUFS or LKFS integrated loudness level smack on the button. Some even more keen eyed might have noticed another loophole. If the target loudness is averaged over the entire program, what's to stop you having some really quiet sections so you can really blast the loud parts, the average would stay the same? The EBU's PLOUD working group thought of this too and introduced a gating system, if the audio drops 10LUFS below the target integrated loudness the integrated loudness measurement is paused until the signal rises above this gating threshold. This gating feature was incorporated into ITU-R BS 1770-2 and as the ATSC A85 specifies compliance with whatever the latest ITU-R BS 1770 revision is, it's automatically part of the ATSC specs too now. Bang goes another loophole! The only potential loophole I can see still remaining is that in 5.1 the .1 (LFE channel) is not currently part of the loudness measurement but as this channel is bandlimited to 20Hz -120Hz I can't see a great deal of mileage in this loophole and anyway, I've just read that the EBU are working on getting a new ITU revision to plug this loophole too. Audio post professionals have had access to these new loudness metering tools for about 3 years or so now and so far no one (that I know of) has found any tricks or cheats to make program material sound louder, as we used to, often within days of them changing the old (pre-loudness) specs. Of course, the advertising agencies at first tried to get us to still make louder mixes but our answer is "sure, no problem but you realise that in the US, Canada and other places it can't be broadcast because it would be against the law and in the EU it will be rejected by the broadcasters"... Q: " I want a louder mix though, what can I do?" A: "Get the ITU to change their specs and/or the US and other countries to change their laws" ... [silence] ....
")
So, it looks like the whole thing is actually working as intended and other areas of the audio industry are taking note. iTunes Radio has implemented a version of loudness normalisation and so has Spotify and the EBU is currently working on coming up with a version for all Radio broadcasters/stations. The theatrical film industry has always used a system of making sure the calibration of full-sized Mix Stages matched the calibration of the cinemas (0VU = 1.223v = -20dBFS = 85dBSPL) and therefore what's too loud in the cinema would also be too loud on the Mix Stage but this system, which has worked well for many years, is starting to fail (for various reasons). I think eventually we'll see loudness normalisation come to theatrical films too but to theatrical trailers and commercials first. It also seems extremely likely that some of the more quality conscious VOD distributors will eventually implement loudness normalisation, NetFlix and iTunes for sure, "when?" is the only question in my mind. As I've mentioned many times here, Youtube has no audio standards, but a sort of convention than many audio post pros are currently using for professional quality content heading for Youtube is an integrated loudness of -16LUFS/LKFS.
I haven't really mentioned LRA, which is essentially dynmanic range in terms of the loudness scale. At the moment I haven't seen any specs which specify an LRA target value or maximum, so far us professionals are just using our own judgement but I'm sure we'll start to see it specified at some stage. There are of course many other areas of broadcaster and distributor audio specs which I haven't covered, I've only covered the basic loudness measurement part of modern TV audio specs.
I should mention another caveat; some/much of the information I've presented in these posts is massively simplified. So much so that in some cases I've had to sail close to the wind of actually ending up presenting inaccurate information. Hopefully I've not actually crossed any boundaries though.
Fire away if there are any questions, I'm sure my simplified explanations have created some gaps which may cause some misunderstandings ....
G